Good Conduct on TACC's HPC Systems
Last Update: July 6, 2026
Notices
- See updated guidance for AI users below. (04/24/2026)
- VSCode users please see below for updated guidance. (11/05/2025)
You share TACC's HPC resources with many, sometimes hundreds, of other users, and what you do on the resource affects other users. All TACC account holders must follow a set of good practices which entail limiting activities that may impact the system for other users. Exercise good conduct to ensure that your activity does not adversely impact the resource and the research community with whom you share it.
Please familiarize yourself with the following guidelines to good conduct on all TACC resources.
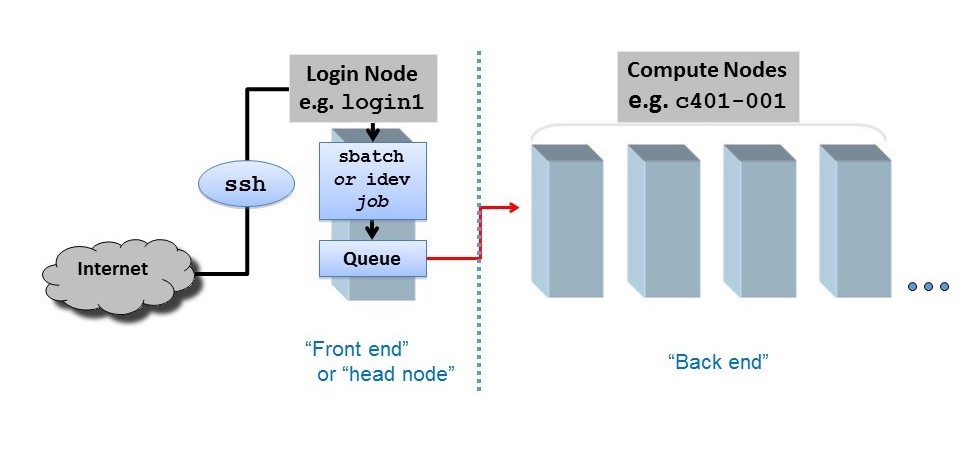
1. Do Not Run Jobs on the Login Nodes
Each HPC system's login nodes are a shared resource amongst all users currently logged on. Depending on the system, dozens, or even hundreds, of users may be logged on at one time accessing the shared file systems. A single user running computationally expensive or disk intensive task/s may negatively impact performance for all other users.
Important
Do not run jobs or perform intensive computational activity on the login nodes or the shared file systems. Your account may be suspended if your jobs are impacting other users.
Think of the login nodes as a prep area, where you may edit and manage files, compile code, perform file management, issue transfers, submit new and track existing batch jobs etc. The login nodes provide an interface to the "back-end" compute nodes, where actual computations occur and where research is done. Hundreds of jobs may be running on all compute nodes, with hundreds more queued up to run.
All batch jobs and executables, as well as development and debugging sessions, must be run on the compute nodes. To access compute nodes on TACC resources, one must either submit a job to a batch queue or initiate an interactive session using the idev utility.
Tip
The login nodes have throttled memory limits for individual processes in order to prevent users from occupying more than their fair portion of the shared resource. The compute nodes do not have this limitation.
AI Tools on TACC Resources
Please be aware of the following policies regarding the use of Artificial Intelligence agents and tools on TACC resources.
- All AI-assisted workloads must be executed on compute nodes only.
- YOU are responsible for all your processes initiated on TACC resources, including those launched via AI tools or agents.
- All Service Units (SUs) consumed by AI-related workloads will be charged against your allocation.
Suggested Workflow:
- Grab one or more compute nodes via TACC's
idevutility. - Once your
idevsession begins, then use your AI tool to connect to the alloted compute node/s.
Warning
Failure to follow these guidelines will result in degraded access to TACC resources or administrative action to protect system stability.
VSCode Users
VSCode consumes significant resources when running and can interfere with the needs of a multi-user environment such as each resource's shared login nodes. TACC staff encourages all VSCode users to run the program on a compute node and not any of the login nodes.
Warning
Using VSCode to access TACC's Ranch and Corral storage resources is prohibited.
Dos & Don'ts on the Login Nodes
-
Do not run research applications on the login nodes;
This includes frameworks like MATLAB and R, as well as computationally or I/O intensive Python scripts. If you need interactive access, use the
idevutility or Slurm'ssrunto schedule one or more compute nodes.
-
Do not launch too many simultaneous processes;
While it's fine to compile on a login node, a command like "
make -j 16" (which compiles on 16 cores) may impact other users. Similarly, do not launch too many transfer sessions on the login nodes.
- That script you wrote to poll job status should probably do so once every few minutes rather than several times a second.
2. Do Not Stress the Shared File Systems
TACC HPC resources, with a few exceptions, each mount three file systems: /home, /work and /scratch. Please follow each file system's recommended usage.
The TACC Global Shared File System, Stockyard, is mounted on most TACC HPC resources as the /work ($WORK) directory and is also a shared resource. This file system is accessible to all TACC users, and therefore experiences a lot of I/O activity (reading and writing to disk, opening and closing files) as users run their jobs, read and generate data including intermediate and checkpointing files. As TACC adds more users, the stress on the $WORK file system has increased to the extent that TACC staff now recommends new job submission guidelines in order to reduce stress and I/O on Stockyard.
Important
TACC staff recommends that you run your jobs out of the $SCRATCH file system instead of the global $WORK file system.
Compute nodes should not reference $WORK unless it's to stage data in/out only before/after jobs. To run your jobs out $SCRATCH:
- Copy or move all job input files to
$SCRATCH - Make sure your job script directs all output to
$SCRATCH - Once your job is finished, move your output files to
$WORKto avoid any data purges.
Consider that $HOME and $WORK are for storage and keeping track of important items. Actual job activity, reading and writing to disk, should be offloaded to your resource's $SCRATCH file system (see File System Usage Recommendations. You can start a job from anywhere but the actual work of the job should occur only on the $SCRATCH partition. You can save original items to $HOME or $WORK so that you can copy them over to $SCRATCH if you need to re-generate results.
- Run I/O intensive jobs in
$SCRATCHrather than$WORK. If you stress$WORK, you affect every user on every TACC system. Significant I/O might include reading/writing 100+ GBs to checkpoint/restart files, running with 4096+ MPI tasks all reading/writing individual files, but is not limited to just those two cases. If you stress$WORK, you affect every user on every TACC system.
File System Usage Recommendations
TACC resources mount three file systems: /home, /work and /scratch. Please follow each file system's recommended usage.
| File System | Best Storage Practices | Best Activities |
|---|---|---|
$HOME |
cron jobs small scripts environment settings |
compiling, editing |
$WORK |
store software installations original datasets that can't be reproduced job scripts and templates |
staging datasets |
$SCRATCH |
Temporary Storage I/O files job files temporary datasets |
all job I/O activity see TACC's Scratch File System Purge Policy. |
Scratch File System Purge Policy
Warning
The $SCRATCH file system, as its name indicates, is a temporary storage space. Files that have not been accessed* in ten days are subject to purge.
Deliberately modifying file access time, using any method, tool, or program, for the purpose of circumventing purge policies is prohibited.
*The operating system updates a file's access time when that file is modified on a login or compute node. Reading or executing a file/script on a login node does not update the access time, but reading or executing on a compute node does update the access time. This approach helps us distinguish between routine management tasks (e.g. tar, scp) and production use. Use the command ls -ul to view access times.
More File System Tips
-
Don't run jobs in your
$HOMEdirectory. The$HOMEfile system is for routine file management, not parallel jobs. -
Watch all your file system quotas. If you're near your quota in
$WORKand your job is repeatedly trying (and failing) to write to$WORK, you will stress that file system. If you're near your quota in$HOME, jobs run on any file system may fail, because all jobs write some data to the hidden$HOME/.slurmdirectory. -
Avoid storing many small files in a single directory, and avoid workflows that require many small files. A few hundred files in a single directory is probably fine; tens of thousands is almost certainly too many. If you must use many small files, group them in separate directories of manageable size.
3. Limit Input/Output (I/O) Activity
In addition to the file system tips above, it's important that your jobs limit all I/O activity. This section focuses on ways to avoid causing problems on each resources' shared file systems.
-
Limit I/O intensive sessions (lots of reads and writes to disk, rapidly opening or closing many files)
-
Avoid opening and closing files repeatedly in tight loops. Every open/close operation on the file system requires interaction with the MetaData Service (MDS). The MDS acts as a gatekeeper for access to files on Lustre's parallel file system. Overloading the MDS will affect other users on the system. If possible, open files once at the beginning of your program/workflow, then close them at the end.
-
Don't get greedy. If you know or suspect your workflow is I/O intensive, don't submit a pile of simultaneous jobs. Writing restart/snapshot files can stress the file system; avoid doing so too frequently. Also, use the
hdf5ornetcdflibraries to generate a single restart file in parallel, rather than generating files from each process separately.
Important
If you know your jobs will require significant I/O, please submit a support ticket and an HPC consultant will work with you. See also Managing I/O on TACC Resources for additional information.
4. File Transfer Guidelines
In order to not stress both internal and external networks, be mindful of the following guidelines:
-
When creating or transferring large files to Stockyard (
$WORK) or the$SCRATCHfile systems, be sure to stripe the receiving directories appropriately. -
Avoid too many simultaneous file transfers. You share the network bandwidth with other users; don't use more than your fair share. Two or three concurrent
scpsessions is probably fine. Twenty is probably not. -
Avoid recursive file transfers, especially those involving many small files. Create a
.tararchive before transfers. This is especially true when transferring files to or from Ranch.
5. Job Submission Tips
-
Request Only the Resources You Need Make sure your job scripts request only the resources that are needed for that job. Don't ask for more time or more nodes than you really need. The scheduler will have an easier time finding a slot for a job requesting 2 nodes for 2 hours, than for a job requesting 4 nodes for 24 hours. This means shorter queue waits times for you and everybody else.
-
Test your submission scripts. Start small: make sure everything works on 2 nodes before you try 20. Work out submission bugs and kinks with 5 minute jobs that won't wait long in the queue and involve short, simple substitutes for your real workload: simple test problems;
hello worldcodes; one-liners likeibrun hostname; or anlddon your executable. -
Respect memory limits and other system constraints. If your application needs more memory than is available, your job will fail, and may leave nodes in unusable states. Use TACC's Remora tool to monitor your application's needs.