Stampede3 User Guide
Last update: June 2, 2026
Notices
- Queue Restriction: Do not request or exclude specific compute nodes when submitting jobs without prior approval from TACC staff. You must allow Slurm to allocate nodes to your jobs. (06/12/2026)
-
Using Artificial Intelligence (AI) clients on TACC resources: We strongly recommend you run all AI assisted tasks on a compute node. Consult the Good Conduct Guide guide for instructions on the use of AI tools and agents. (05/07/2026)
Important
- You are responsible for any processes launched on TACC resources via any AI process.
- Any and all SUs consumed by an AI process launched by you will be charged to your allocation.
Introduction
The National Science Foundation (NSF) has generously awarded the University of Texas at Austin funds for TACC's Stampede3 system (Award Abstract # 2320757). Please reference TACC when providing any citations.
Allocations
Submit all Stampede3 allocations requests through the NSF's ACCESS project. General information related to allocations, support and operations is available via the ACCESS website http://access-ci.org.
Requesting and managing allocations will require creating a username and password on this site. These credentials do not have to be the same as those used to access the TACC User Portal and TACC resources. Principal Investigators (PIs) and their allocation managers will be able to add/remove users to/from their allocations and submit requests to renew, supplement, extend, etc. their allocations. PIs attempting to manage an allocation via the TACC User Portal will be redirected to the ACCESS website.
System Architecture
Ice Lake Large Memory Nodes
Stampede3 hosts 3 large memory "Ice Lake" (ICX) nodes. Access these nodes via the nvdimm queue.
Table 1. ICX NVDIMM Specifications
| Specification | Value |
|---|---|
| CPU: | Intel Xeon Platinum 8380 ("Ice Lake") |
| Total cores: | 80 cores on two sockets (40 cores/socket) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 80 |
| Clock rate: | 2.3 GHz nominal (3.4GHz max frequency depending on instruction set and number of active cores) |
| RAM: | 4TB NVDIMM |
| Cache: | 48KB L1 data cache per core; 1.25 MB L2 per core; 60 MB L3 per socket. Each socket can cache up to 110 MB (sum of L2 and L3 capacity) |
| Local storage: | 280GB /tmp partition |
Ice Lake Compute Nodes
Stampede3 hosts 224 "Ice Lake" (ICX) compute nodes.
Table 2. ICX Specifications
| Specification | Value |
|---|---|
| CPU: | Intel Xeon Platinum 8380 ("Ice Lake") |
| Total cores per ICX node: | 80 cores on two sockets (40 cores/socket) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 80 |
| Clock rate: | 2.3 GHz nominal (3.4GHz max frequency depending on instruction set and number of active cores) |
| RAM: | 256GB (3.2 GHz) DDR4 |
| Cache: | 48KB L1 data cache per core; 1.25 MB L2 per core; 60 MB L3 per socket. Each socket can cache up to 110 MB (sum of L2 and L3 capacity) |
| Local storage: | 200 GB /tmp partition |
Sapphire Rapids Compute Nodes
Stampede3 hosts 560 "Sapphire Rapids" HBM (SPR) nodes with 112 cores each. Each SPR node provides a performance increase of 2 - 3x over the SKX nodes due to increased core count and greatly increased memory bandwidth. The available memory bandwidth per core increases by a factor of 3.5x. Applications that were starved for memory bandwidth should exhibit improved performance close to 3x.
Table 3. SPR Specifications
| Specification | Value |
|---|---|
| CPU: | Intel Xeon CPU MAX 9480 ("Sapphire Rapids HBM") |
| Total cores per node: | 112 cores on two sockets (2 x 56 cores) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 2x56 = 112 |
| Clock rate: | 1.9GHz |
| Memory: | 128 GB HBM 2e |
| Cache: | 48 KB L1 data cache per core; 1MB L2 per core; 112.5 MB L3 per socket. Each socket can cache up to 168.5 MB (sum of L2 and L3 capacity). |
| Local storage: | 150 GB /tmp partition |
Skylake Compute Nodes
Stampede3 hosts 1,060 "Skylake" (SKX) compute nodes.
Table 4. SKX Specifications
| Specification | Value |
|---|---|
| Model: | Intel Xeon Platinum 8160 ("Skylake") |
| Total cores per SKX node: | 48 cores on two sockets (24 cores/socket) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 48 |
| Clock rate: | 2.1GHz nominal (1.4-3.7GHz depending on instruction set and number of active cores) |
| RAM: | 192GB (2.67GHz) DDR4 |
| Cache: | 32 KB L1 data cache per core; 1 MB L2 per core; 33 MB L3 per socket. Each socket can cache up to 57 MB (sum of L2 and L3 capacity). |
| Local storage: | 90 GB /tmp |
GPU Nodes
Stampede3 hosts two types of GPU nodes, Intel's Ponte Vecchio and NVIDIA's H100 nodes, accessible through the pvc and h100 queues respectively.
H100 nodes
Stampede3 has 24 H100 nodes.
Table 5a. H100 Specifications
| Specification | Value |
|---|---|
| GPU: | 4x NVIDIA H100 SXM5 |
| GPU Memory: | 96GB |
| CPU: | Intel Xeon Platinum 8468 ("Sapphire Rapids") |
| Total cores per node: | 96 cores on two sockets (2 x 48 cores) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 2x48 = 96 |
| Clock rate: | 2.10 GHz |
| Memory: | 1TB DDR5 |
| Cache: | 80 KB L1 per core; 2MB L2 per core; 105 MB per socket |
| Local Storage: | 3.5 TB /tmp partition |
| Additional Fabric: | Mellanox InfiniBand NDR (split ports 200Gb/s) direct-GPU |
Ponte Vecchio Compute Nodes
Stampede3 hosts 20 nodes with four Intel Data Center GPU Max 1550s "Ponte Vecchio" (PVC) each.
Each PVC GPU has two 62GB tiles of video memory each, for a combined 124GB of memory per GPU.
Table 5b. PVC Specifications
| Specification | Value |
|---|---|
| GPU: | 4x Intel Data Center GPU Max 1550s ("Ponte Vecchio") |
| GPU Memory: | 62 GB per tile; 124 GB per GPU |
| CPU: | Intel Xeon Platinum 8480 ("Sapphire Rapids") |
| Total cores per node: | 96 cores on two sockets (2 x 48 cores) |
| Hardware threads per core: | 1 |
| Hardware threads per node: | 2x48 = 96 |
| Clock rate: | 2.10 GHz |
| Memory: | 1TB DDR5 |
| Cache: | 80 KB L1 per core; 2MB L2 per core; 105 MB per socket |
| Local storage: | 3.5 TB /tmp partition |
Login Nodes
The Stampede3 login nodes are Intel Xeon Platinum 8468 "Sapphire Rapids" (SPR) nodes, each with 96 cores on two sockets (48 cores/socket) with 250 GB of DDR.
Network
The interconnect is a 100Gb/sec Omni-Path (OPA) network with a fat tree topology. There is one leaf switch for each 28-node half rack, each with 20 leaf-to-core uplinks (28/20 oversubscription) for the SKX nodes. The ICX and SKX nodes are fully connected. The SPR and PVC nodes are fully connected with a fat tree topology with no oversubscription.
The SPR and PVC networks will be upgraded to use Cornelis' CN5000 Omni-Path technology in 2024. The backbone network will also be upgraded.
File Systems
Stampede3 will use a shared VAST file system for the $HOME and $SCRATCH directories. These two file systems are NOT lustre file systems and do not support setting a stripe count or stripe size. There are no options for the user to set. As with Stampede2, the $WORK file system will also be mounted. Unlike $HOME and $SCRATCH, the $WORK file system is a Lustre file system and supports the lustre lfs commands. All three file systems, $HOME, $SCRATCH, and $WORK are available from all Stampede3 nodes. The /tmp partition is also available to users but is local to each node. The $WORK file system is available on most other TACC HPC systems as well.
Table 6. File Systems
| File System | Quota | Key Features |
|---|---|---|
$HOME |
15 GB, 300,000 files | Not intended for parallel or high−intensity file operations. Backed up regularly. |
$WORK |
1 TB, 3,000,000 files across all TACC systems Not intended for parallel or high−intensity file operations. See Stockyard system description for more information. |
Not backed up. |
$SCRATCH |
no quota Overall capacity ~10 PB. |
Not backed up. Files are subject to purge if access time* is more than 10 days old. See TACC's Scratch File System Purge Policy below. |
Important
TACC will not grant requests for increasing /home and /work quotas. If you require more storage space, TACC's Corral is available at no charge to UT researchers, and at low-cost annual fee to non-UT researchers. See the Corral User Guide for more details.
Scratch File System Purge Policy
Warning
The $SCRATCH file system, as its name indicates, is a temporary storage space. Files that have not been accessed* in ten days are subject to purge.
Deliberately modifying file access time, using any method, tool, or program, for the purpose of circumventing purge policies is prohibited.
*The operating system updates a file's access time when that file is modified on a login or compute node. Reading or executing a file/script on a login node does not update the access time, but reading or executing on a compute node does update the access time. This approach helps us distinguish between routine management tasks (e.g. tar, scp) and production use. Use the command ls -ul to view access times.
Accessing the System
Access to all TACC systems requires Multi-Factor Authentication (MFA). You can create an MFA pairing under "Manage Account" in the TACC Portal. See Multi-Factor Authentication at TACC for further information.
Important
You will be able to log on to Stampede3 only if you have an allocation on Stampede3, otherwise your password will be rejected.
Monitor your projects & allocations the via the TACC Portal.
Secure Shell (SSH)
The ssh command (Secure Shell, or SSH protocol) is the standard way to connect to Stampede3 and initiate a login session. SSH also includes support for the UNIX file transfer utilities scp and sftp. These commands are available within Linux and the Terminal application within Mac OS. If you are using Windows, you will need a modern terminal application such as Windows Terminal, MobaXterm or Cyberduck.
Initiate an SSH session using the ssh command or the equivalent:
localhost$ ssh myusername@stampede3.tacc.utexas.edu
The above command will rotate connections across all available login nodes and route your connection to the next available node.
Important
Stampede3's login nodes are a shared resource. See TACC's Good Conduct Policy for more information.
To connect to a specific login node, use its full domain name:
localhost$ ssh myusername@login2.stampede3.tacc.utexas.edu
To connect with X11 support on Stampede3 (usually required for applications with graphical user interfaces), use the -X or -Y option:
localhost$ ssh -X myusername@stampede3.tacc.utexas.edu
Use your TACC portal password for direct logins to TACC resources. You can change or reset your TACC password via the TACC Portal under "Manage Account". To report a connection problem, execute the ssh command with the -vvv option and include this command's verbose output when submitting a help ticket.
Do not run the ssh-keygen command on Stampede3. This command will create and configure a key pair that will interfere with the execution of job scripts in the batch system. If you do this by mistake, you can recover by renaming or deleting the .ssh directory located in your home directory; the system will automatically generate a new pair for you when you next log into Stampede3.
- execute
mv .ssh dot.ssh.old - log out
- log into Stampede3 again
After logging in again, the system will generate a properly configured key SSH pair.
Account Administration
This section explores ways to configure and manage your Linux account on Stampede3. Stampede3 nodes run Rocky Linux. Regardless of your research workflow, you'll likely need to master Linux command-line basics along with a Linux-based text editor (e.g. emacs, nano, gedit, or vi/vim) to use the system properly. If you encounter a term or concept in this user guide that is new to you, a quick internet search should help you resolve the matter quickly.
Allocation Status
If your password is rejected while attempting to log in, it's possible your account or project has not been added to a Stampede3 allocation. You can list and manage your allocations via the TACC Portal.
Linux Shell
The default login shell for your user account is Bash. To determine your current login shell, examine the contents of the $SHELL environment variable:
$ echo $SHELLTip
If you'd like to change your login shell to csh, tcsh, or zsh, submit a help ticket.
The chsh ("change shell") command will not work on TACC systems.
When you start a shell on Stampede3, system-level startup files initialize your account-level environment and aliases before the system sources your own user-level startup scripts. You can use these startup scripts to customize your shell by defining your own environment variables, aliases, and functions. These scripts (e.g. .profile and .bashrc) are generally hidden files: so-called "dotfiles" that begin with a period, visible when you execute: ls -a.
Before editing your startup files, however, it's worth taking the time to understand the basics of how your shell manages startup. Bash startup behavior is very different from the simpler csh behavior, for example. The Bash startup sequence varies depending on how you start the shell (e.g. using ssh to open a login shell, executing the bash command to begin an interactive shell, or launching a script to start a non-interactive shell). Moreover, Bash does not automatically source your .bashrc file when you start a login shell by using ssh to connect to a node. Unless you have specialized needs, however, this is undoubtedly more flexibility than you want: you will probably want your environment to be the same regardless of how you start the shell. The easiest way to achieve this is to execute source ~/.bashrc from your .profile, then put all your customizations in your .bashrc file. The system-generated default startup scripts demonstrate this approach. We recommend that you use these default files as templates.
For more information see the Bash Users' Startup Files: Quick Start Guide and other online resources that explain shell startup. To recover the originals that appear in a newly created account, execute /usr/local/startup_scripts/install_default_scripts.
Diagnostics
TACC's sanitytool module loads an account-level diagnostic package that detects common account-level issues and often walks you through the fixes. You should certainly run the package's sanitycheck utility when you encounter unexpected behavior. You may also want to run sanitycheck periodically as preventive maintenance. To run sanitytool's account-level diagnostics, execute the following commands:
login1$ module load sanitytool
login1$ sanitycheckExecute module help sanitytool for more information.
Environment Variables
Your environment includes the environment variables and functions defined in your current shell: those initialized by the system, those you define or modify in your account-level startup scripts, and those defined or modified by the modules that you load to configure your software environment. Be sure to distinguish between an environment variable's name (e.g. HISTSIZE) and its value ($HISTSIZE). Understand as well that a sub-shell (e.g. a script) inherits environment variables from its parent, but does not inherit ordinary shell variables or aliases. Use export (in Bash) or setenv (in csh) to define an environment variable.
Execute the env command to see the environment variables that define the way your shell and child shells behave.
Pipe the results of env into grep to focus on specific environment variables. For example, to see all environment variables that contain the string GIT (in all caps), execute:
$ env | grep GITThe environment variables PATH and LD_LIBRARY_PATH are especially important. The PATH is a colon-separated list of directory paths that determines where the system looks for your executables. The LD_LIBRARY_PATH environment variable is a similar list that determines where the system looks for shared libraries.
Using Modules
Lmod, a module system developed and maintained at TACC, makes it easy to manage your environment so you have access to the software packages and versions that you need to using your research. This is especially important on a system like Stampede3 that serves thousands of users with an enormous range of needs and software. Loading a module amounts to choosing a specific package from among available alternatives:
$ module load intel # load the default Intel compiler
$ module load intel/24.0.0 # load a specific version of Intel compilerA module does its job by defining or modifying environment variables (and sometimes aliases and functions). For example, a module may prepend appropriate paths to $PATH and $LD_LIBRARY_PATH so that the system can find the executables and libraries associated with a given software package. The module creates the illusion that the system is installing software for your personal use. Unloading a module reverses these changes and creates the illusion that the system just uninstalled the software:
$ module load ddt # defines DDT-related env vars; modifies others
$ module unload ddt # undoes changes made by loadThe module system does more, however. When you load a given module, the module system can automatically replace or deactivate modules to ensure the packages you have loaded are compatible with each other. In the example below, the module system automatically unloads one compiler when you load another, and replaces Intel-compatible versions of IMPI and PETSc with versions compatible with gcc:
$ module load intel # load default version of Intel compiler
$ module load petsc # load default version of PETSc
$ module load gcc # change compiler
Lmod is automatically replacing "intel/24.0.0" with "gcc/13.2.0".
Due to MODULEPATH changes, the following have been reloaded:
1) impi/21.11 2) petsc/3.8Tip
See Lmod's documentation for extensive information. The online documentation addresses the basics in more detail, but also covers several topics beyond the scope of the help text (e.g. writing and using your own module files).
On Stampede3, modules generally adhere to a TACC naming convention when defining environment variables that are helpful for building and running software. For example, the papi module defines TACC_PAPI_BIN (the path to PAPI executables), TACC_PAPI_LIB (the path to PAPI libraries), TACC_PAPI_INC (the path to PAPI include files), and TACC_PAPI_DIR (top-level PAPI directory). After loading a module, here are some easy ways to observe its effects:
$ module show papi # see what this module does to your environment
$ env | grep PAPI # see env vars that contain the string PAPI
$ env | grep -i papi # case-insensitive search for 'papi' in environmentTo see the modules you currently have loaded:
$ module listTo see all modules that you can load right now because they are compatible with the currently loaded modules:
$ module availTo see all installed modules, even if they are not currently available because they are incompatible with your currently loaded modules:
$ module spider # list all modules, even those not available to loadTo filter your search:
$ module spider slep # all modules with names containing 'slep'
$ module spider sundials/2.5.0 # additional details on a specific moduleAmong other things, the latter command will tell you which modules you need to load before the module is available to load. You might also search for modules that are tagged with a keyword related to your needs (though your success here depends on the diligence of the module writers). For example:
$ module keyword performanceYou can save a collection of modules as a personal default collection that will load every time you log into Stampede3. To do so, load the modules you want in your collection, then execute:
$ module save # save the currently loaded collection of modulesTwo commands make it easy to return to a known, reproducible state:
$ module reset # load the system default collection of modules
$ module restore # load your personal default collection of modulesOn TACC systems, the command module reset is equivalent to module purge; module load TACC. It's a safer, easier way to get to a known baseline state than issuing the two commands separately.
Help text is available for both individual modules and the module system itself:
$ module help swr # show help text for software package swr
$ module help # show help text for the module system itselfIt's safe to execute module commands in job scripts. In fact, this is a good way to write self-documenting, portable job scripts that produce reproducible results. If you use module save to define a personal default module collection, it's rarely necessary to execute module commands in shell startup scripts, and it can be tricky to do so safely. If you do wish to put module commands in your startup scripts, see Stampede3's default startup scripts in /usr/local/startup_scripts for a safe way to do so.
Crontabs
TACC allows cronjobs but be aware that crontab files are unique to the login node where they were created and are not shared across the login nodes. Crontab files are not allowed on the compute nodes.
Note
All TACC HPC systems host multiple login nodes. When you login, your connection is routed to the next available login node via round-robin DNS. This practice balances the user load across the system.
When creating a crontab file, use the hostname command to determine your exact location, and make note of it:
$ hostname
login2.stampede3.tacc.utexas.eduSimilarly you can always connect to that login node by specifying its full domain name:
localhost$ ssh login2.stampede3.tacc.utexas.eduImportant
As with any computation, ensure that cronjobs are run only on the compute nodes
TACC Tips
TACC staff has amassed a database of helpful tips for our users. Access these tips via the tacc_tips module and showTip command as demonstrated below:
$ module load tacc_tips
$ showTip
Tip 40 (See "module help tacc_tips" for features or how to disable)
Here are four different ways to repeat the last executed command (press enter after each):
* Use the up arrow
* Type !!
* Type !-1
* Press Ctrl+PManaging Your Files
Stampede3 mounts three file systems that are shared across all nodes: the home, work, and scratch file systems. Stampede3's startup mechanisms define corresponding account-level environment variables $HOME, $SCRATCH, and $WORK that store the paths to directories that you own on each of these file systems. Consult the Stampede3 File Systems table for the basic characteristics of these file systems, File Operations: I/O Performance for advice on performance issues, and Good Conduct for tips on file system etiquette.
Tip
Each "Active" TACC account user is allocated 1TB of space across the shared /work (Stockyard) file system, as well as 2TB on TACC's archival system, Ranch.
Navigating the Shared File Systems
Stampede3's /home and /scratch file systems are mounted only on Stampede3, but the work file system mounted on Stampede3 is the Global Shared File System hosted on Stockyard. Stockyard is the same work file system that is currently available on Frontera, Lonestar6, and several other TACC resources.
The $STOCKYARD environment variable points to the highest-level directory that you own on the Global Shared File System. The definition of the $STOCKYARD environment variable is of course account-specific, but you will see the same value on all TACC systems that provide access to the Global Shared File System. This directory is an excellent place to store files you want to access regularly from multiple TACC resources.
Your account-specific $WORK environment variable varies from system to system and is a sub-directory of $STOCKYARD (Figure 1). The sub-directory name corresponds to the associated TACC resource. The $WORK environment variable on Stampede3 points to the $STOCKYARD/stampede3 subdirectory, a convenient location for files you use and jobs you run on Stampede3. Remember, however, that all subdirectories contained in your $STOCKYARD directory are available to you from any system that mounts the file system. If you have accounts on both Stampede3 and Frontera, for example, the $STOCKYARD/stampede3 directory is available from your Frontera account, and $STOCKYARD/frontera is available from your Stampede3 account.
Note
Your quota and reported usage on the Global Shared File System reflects all files that you own on Stockyard, regardless of their actual location on the file system.
See the example for fictitious user bjones in the figure below. All directories are accessible from all systems, however a given sub-directory (e.g. lonestar6, frontera) will exist only if you have an allocation on that system. Figure 1 below illustrates account-level directories on the $WORK file system (Global Shared File System hosted on Stockyard).
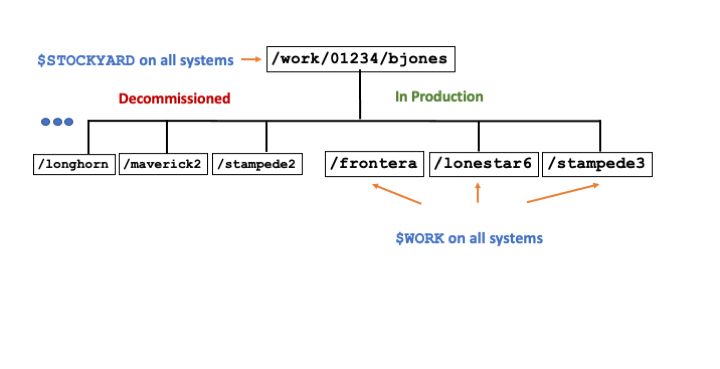
Note that the resource-specific sub-directories of $STOCKYARD are nothing more than convenient ways to manage your resource-specific files. You have access to any such sub-directory from any TACC resources. If you are logged into Stampede3, for example, executing the alias cdw (equivalent to cd $WORK) will take you to the resource-specific sub-directory $STOCKYARD/stampede3. But you can access this directory from other TACC systems as well by executing cd $STOCKYARD/stampede3. These commands allow you to share files across TACC systems. In fact, several convenient account-level aliases make it even easier to navigate across the directories you own in the shared file systems:
Table 7. Built-in Account Level Aliases
| Alias | Command |
|---|---|
cd or cdh |
cd $HOME |
cdw |
cd $WORK |
cds |
cd $SCRATCH |
cdy or cdg |
cd $STOCKYARD |
Sharing Files with Collaborators
If you wish to share files and data with collaborators in your project, see Sharing Project Files on TACC Systems for step-by-step instructions. Project managers or delegates can use Unix group permissions and commands to create read-only or read-write shared workspaces that function as data repositories and provide a common work area to all project members.
Running Jobs
Stampede3's job scheduler is the Slurm Workload Manager. Slurm commands enable you to submit, manage, monitor, and control your jobs. Jobs submitted to the scheduler are queued, then run on the compute nodes. Each job consumes Service Units (SUs) which are then charged to your allocation. See the Job Management section below for further information.
Important
Queue limits are subject to change without notice.
Stampede3 admins may occasionally adjust queue settings in order to ensure fair scheduling for the entire user community.
TACC's qlimits utility will display the latest queue configurations.
Table 8. Production Queues
| Queue Name | Node Type | Max Nodes per Job (assoc'd cores) |
Max Job Duration |
Max Nodes per User |
Max Jobs per User |
Max Submit | Charge Rate (per node-hour) |
|---|---|---|---|---|---|---|---|
| h100 | H100 | 4 nodes (384 cores) |
48 hrs | 4 | 2 | 4 | 4 SUs |
| icx | ICX | 32 nodes (2560 cores) |
48 hrs | 48 | 12 | 20 | 1.5 SUs |
| nvdimm | ICX | 1 node (80 cores) |
48 hrs | 1 | 2 | 4 | 4 SUs |
| pvc | PVC | 4 nodes (384 cores) |
48 hrs | 4 | 2 | 4 | 3 SUs |
| skx | SKX | 256 nodes (12288 cores) |
48 hrs | 256 | 40 | 60 | 1 SU |
| skx-dev | SKX | 16 nodes (768 cores) |
2 hrs | 16 | 2 | 4 | 1 SU |
| spr | SPR | 32 nodes (3584 cores) |
48 hrs | 40 | 24 | 36 | 2 SUs |
Job Accounting
Like all TACC systems, Stampede3's accounting and allocation system is based on node-hours: one unadjusted Service Unit (SU) represents a single compute node used for one hour (a node-hour). For any given job, the total cost in SUs is the use of one compute node for one hour of wall clock time plus any charges or discounts for the use of specialized queues, e.g. Stampede3's pvc queue, Lonestar6's gpu-a100 queue, and Frontera's flex queue. The queue charge rates are determined by the supply and demand for that particular queue or type of node used and are subject to change.
The Slurm scheduler tracks and charges for usage to a granularity of a few seconds of wall clock time. The system charges only for the resources you actually use, not those you request. If your job finishes early and exits properly, Slurm will release the nodes back into the pool of available nodes. Your job will only be charged for as long as you are using the nodes.
TACC does not implement node-sharing on any compute resource. Each Stampede3 compute node can be assigned to only one user at a time; hence a complete node is dedicated to a user's job and accrues wall-clock time for all the node's cores/GPUs whether or not all cores/GPUs are used.
TACC Charging Policy
Stampede3 SUs billed = (# nodes) x max(job duration in wall clock hours,.25) x (charge rate per node-hour)
All running jobs are charged a minimum of 15 minutes (.25 hrs) of queue time regardless of actual runtime. This policy ensures equal access to the queues for all users as TACC's user base expands.
For example: a 4-node job in Stampede3's spr queue which runs for five minutes would be charged as follows:
4 nodes * 0.25 hrs * 2 SUs/node-hour = 2 SUs
We strongly encourage users launching large jobs to do thorough testing of your code at smaller node counts prior to maximizing your runs.
Submitting Batch Jobs with sbatch
Use Slurm's sbatch command to submit a batch job to one of the Stampede3 queues:
login1$ sbatch myjobscriptWhere myjobscript is the name of a text file containing #SBATCH directives and shell commands that describe the particulars of the job you are submitting. The details of your job script's contents depend on the type of job you intend to run.
In your job script you (1) use #SBATCH directives to request computing resources (e.g. 10 nodes for 2 hrs); and then (2) use shell commands to specify what work you're going to do once your job begins. There are many possibilities: you might elect to launch a single application, or you might want to accomplish several steps in a workflow. You may even choose to launch more than one application at the same time. The details will vary, and there are many possibilities. But your own job script will probably include at least one launch line that is a variation of one of the examples described here.
Your job will run in the environment it inherits at submission time; this environment includes the modules you have loaded and the current working directory. In most cases you should run your applications(s) after loading the same modules that you used to build them. You can of course use your job submission script to modify this environment by defining new environment variables; changing the values of existing environment variables; loading or unloading modules; changing directory; or specifying relative or absolute paths to files. Do not use the Slurm --export option to manage your job's environment: doing so can interfere with the way the system propagates the inherited environment.
Table 9. below describes some of the most common sbatch command options. Slurm directives begin with #SBATCH; most have a short form (e.g. -N) and a long form (e.g. --nodes). You can pass options to sbatch using either the command line or job script; most users find that the job script is the easier approach. The first line of your job script must specify the interpreter that will parse non-Slurm commands; in most cases #!/bin/bash or #!/bin/csh is the right choice. Avoid #!/bin/sh (its startup behavior can lead to subtle problems on Stampede3), and do not include comments or any other characters on this first line. All #SBATCH directives must precede all shell commands. Note also that certain #SBATCH options or combinations of options are mandatory, while others are not available on Stampede3.
y default, Slurm writes all console output to a file named "slurm-%j.out", where %j is the numerical job ID. To specify a different filename use the -o option. To save stdout (standard out) and stderr (standard error) to separate files, specify both -o and -e options.
Tip
The maximum runtime for any individual job is 48 hours. However, if you have good checkpointing implemented, you can easily chain jobs such that the outputs of one job are the inputs of the next, effectively running indefinitely for as long as needed. See Slurm's -d option.
Table 9. Common sbatch Options
| Option | Argument | Comments |
|---|---|---|
-A |
projectid | Charge job to the specified project/allocation number. This option is only necessary for logins associated with multiple projects. |
-aor --array |
=tasklist | Stampede3 supports Slurm job arrays. See the Slurm documentation on job arrays for more information. |
-d= |
afterok:jobid | Specifies a dependency: this run will start only after the specified job (jobid) successfully finishes |
-export= |
N/A | Avoid this option on Stampede3. Using it is rarely necessary and can interfere with the way the system propagates your environment. |
--gres |
N/A | Stampede3 does not support this option. Slurm will reject any script with this directive. |
--gpus-per-task |
N/A | Stampede3 does not support this option. Slurm will reject any script with this directive. |
-p |
queue_name | Submits to queue (partition) designated by queue_name |
-J |
job_name | Job Name |
-N |
total_nodes | Required. Define the resources you need by specifying either: (1) -N and -n; or(2) -N and -ntasks-per-node. |
-n |
total_tasks | This is total MPI tasks in this job. See -N above for a good way to use this option. When using this option in a non-MPI job, it is usually best to set it to the same value as -N. |
-ntasks-per-nodeor -tasks-per-node |
tasks_per_node | This is MPI tasks per node. See -N above for a good way to use this option. When using this option in a non-MPI job, it is usually best to set -ntasks-per-node to 1. |
-t |
hh:mm:ss | Required. Wall clock time for job. |
-mail-type= |
begin, end, fail, or all |
Specify when user notifications are to be sent (one option per line). |
-mail-user= |
email_address | Specify the email address to use for notifications. Use with the -mail-type= flag above. |
-o |
output_file | Direct job standard output to output_file (without -e option error goes to this file) |
-e |
error_file | Direct job error output to error_file |
-mem |
N/A | Not available. If you attempt to use this option, the scheduler will not accept your job. |
Launching Applications
The primary purpose of your job script is to launch your research application. How you do so depends on several factors, especially (1) the type of application (e.g. MPI, OpenMP, serial), and (2) what you're trying to accomplish (e.g. launch a single instance, complete several steps in a workflow, run several applications simultaneously within the same job). While there are many possibilities, your own job script will probably include a launch line that is a variation of one of the examples described in this section:
Note that the following examples demonstrate launching within a Slurm job script or an idev session. Do not launch jobs on the login nodes.
One Serial Application
To launch a serial application, simply call the executable. Specify the path to the executable in either the $PATH environment variable or in the call to the executable itself:
myprogram # executable in a directory listed in $PATH
$WORK/apps/myprov/myprogram # explicit full path to executable
./myprogram # executable in current directory
./myprogram -m -k 6 input1 # executable with notional input optionsOne Multi-Threaded Application
Launch a threaded application the same way. Be sure to specify the number of threads. Note that the default OpenMP thread count is 1.
export OMP_NUM_THREADS=48 # 48 total OpenMP threads (1 per SKX core)
./myprogramOne MPI Application
To launch an MPI application, use the TACC-specific MPI launcher ibrun, which is a Stampede3-aware replacement for generic MPI launchers like mpirun and mpiexec. In most cases the only arguments you need are the name of your executable followed by any arguments your executable needs. When you call ibrun without other arguments, your Slurm #SBATCH directives will determine the number of ranks (MPI tasks) and number of nodes on which your program runs.
#SBATCH -N 5
#SBATCH -n 200
ibrun ./myprogram # ibrun uses the $SBATCH directives to properly allocate nodes and tasksibrun interactively, say within an idev session, you can specify:
login1$ idev -N 2 -n 80
c123-456$ ibrun ./myprogram # ibrun uses idev's arguments to properly allocate nodes and tasksOne Hybrid (MPI+Threads) Application
When launching a single application you generally don't need to worry about affinity: both Intel MPI and MVAPICH will distribute and pin tasks and threads in a sensible way.
export OMP_NUM_THREADS=8 # 8 OpenMP threads per MPI rank
ibrun ./myprogram # use ibrun instead of mpirun or mpiexecAs a practical guideline, the product of $OMP_NUM_THREADS and the maximum number of MPI processes per node should not be greater than total number of cores available per node (SPR nodes have 112 cores, ICX nodes have 80 cores, SKX nodes have 48 cores).
More Than One Serial Application in the Same Job
TACC's pylauncher utility provides an easy way to launch more than one serial application in a single job. This is a great way to engage in a popular form of High Throughput Computing: running parameter sweeps (one serial application against many different input datasets) on several nodes simultaneously. The PyLauncher utility will execute your specified list of independent serial commands, distributing the tasks evenly, pinning them to specific cores, and scheduling them to keep cores busy. Consult PyLauncher at TACC for more information.
MPI Applications - Consecutive
To run one MPI application after another (or any sequence of commands one at a time), simply list them in your job script in the order in which you'd like them to execute. When one application/command completes, the next one will begin.
module load git
module list
./preprocess.sh
ibrun ./myprogram input1 # runs after preprocess.sh completes
ibrun ./myprogram input2 # runs after previous MPI app completesMPI Application - Concurrent
To run more than one MPI application simultaneously in the same job, you need to do several things:
- use ampersands to launch each instance in the background;
- include a
waitcommand to pause the job script until the background tasks complete; - use
ibrun's-nand-oswitches to specify task counts and hostlist offsets respectively; and - include a call to the
task_affinityscript in youribrunlaunch line.
If, for example, you use #SBATCH directives to request N=4 nodes and n=128 total MPI tasks, Slurm will generate a hostfile with 128 entries (32 entries for each of 4 nodes). The -n and -o switches, which must be used together, determine which hostfile entries ibrun uses to launch a given application; execute ibrun --help for more information. Don't forget the ampersands (&) to launch the jobs in the background, and the wait command to pause the script until the background tasks complete:
ibrun -n 32 -o 0 task_affinity ./myprogram input1 & # 32 tasks; offset by 0 entries in hostfile.
ibrun -n 32 -o 32 task_affinity ./myprogram input2 & # 32 tasks; offset by 32 entries in hostfile.
wait # Required; else script will exit immediately.The task_affinity script manages task placement and pinning when you call ibrun with the -n, -o switches (it's not necessary under any other circumstances);
More than One OpenMP Application Running Concurrently
You can also run more than one OpenMP application simultaneously on a single node, but you will need to distribute and pin tasks appropriately. In the example below, numactl -C specifies virtual CPUs (hardware threads). According to the numbering scheme for SPR hardware threads, CPU (hardware thread) numbers 0-111 are spread across the 112 cores, 1 thread per core. Similarly for SKX: CPU (hardware thread) numbers 0-47 are spread across the 48 cores, 1 thread per core, and for ICX: CPU (hardware thread) numbers 0-79 are spread across the 80 cores, 1 thread per core.
export OMP_NUM_THREADS=2
numactl -C 0-1 ./myprogram inputfile1 & # HW threads (hence cores) 0-1. Note ampersand.
numactl -C 2-3 ./myprogram inputfile2 & # HW threads (hence cores) 2-3. Note ampersand.
waitInteractive Sessions
Interactive Sessions with idev and srun
TACC's own idev utility is the best way to begin an interactive session on one or more compute nodes. To launch a thirty-minute session on a single node in the development queue, simply execute:
login1$ idevYou'll then see output that includes the following excerpts:
...
-----------------------------------------------------------------
Welcome to the Stampede3 Supercomputer
-----------------------------------------------------------------
...
-> After your `idev` job begins to run, a command prompt will appear,
-> and you can begin your interactive development session.
-> We will report the job status every 4 seconds: (PD=pending, R=running).
->job status: PD
->job status: PD
...
c449-001$The job status messages indicate that your interactive session is waiting in the queue. When your session begins, you'll see a command prompt on a compute node (in this case, the node with hostname c449-001). If this is the first time you launch idev, the prompts may invite you to choose a default project and a default number of tasks per node for future idev sessions.
For command line options and other information, execute idev --help. It's easy to tailor your submission request (e.g. shorter or longer duration) using Slurm-like syntax:
login1$ idev -p skx -N 2 -n 8 -m 150 # skx queue, 2 nodes, 8 total tasks, 150 minutesFor more information see the idev documentation.
You can also launch an interactive session with Slurm's srun command. A typical launch line would look like this:
login1$ srun --pty -N 2 -n 8 -t 2:30:00 -p skx /bin/bash -l # same conditions as aboveInteractive Sessions using ssh
If you have a batch job or interactive session running on a compute node, you "own the node": you can connect via ssh to open a new interactive session on that node. This is an especially convenient way to monitor your applications' progress. One particularly helpful example: login to a compute node that you own, execute top, then press the "1" key to see a display that allows you to monitor thread ("CPU") and memory use.
There are many ways to determine the nodes on which you are running a job, including feedback messages following your sbatch submission, the compute node command prompt in an idev session, and the squeue or showq utilities. The sequence of identifying your compute node then connecting to it would look like this:
login1$ squeue -u bjones
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
858811 skx-dev idv46796 bjones R 0:39 1 c448-004
1ogin1$ ssh c448-004
...
C448-004$Slurm Environment Variables
Be sure to distinguish between internal Slurm replacement symbols (e.g. %j described above) and Linux environment variables defined by Slurm (e.g. SLURM_JOBID). Execute env | grep SLURM from within your job script to see the full list of Slurm environment variables and their values. You can use Slurm replacement symbols like %j only to construct a Slurm filename pattern; they are not meaningful to your Linux shell. Conversely, you can use Slurm environment variables in the shell portion of your job script but not in an #SBATCH directive.
Danger
For example, the following directive will not work the way you might think:
#SBATCH -o myMPI.o${SLURM_JOB_ID} # incorrectHint
Instead, use the following directive:
#SBATCH -o myMPI.o%j # "%j" expands to your job's numerical job IDSimilarly, you cannot use paths like $WORK or $SCRATCH in an #SBATCH directive.
For more information on this and other matters related to Slurm job submission, see the Slurm online documentation; the man pages for both Slurm itself (man slurm) and its individual commands (e.g. man sbatch); as well as numerous other online resources.
Building Software
Important
TACC maintains a database of currently installed software packages and libraries across all HPC resources. Navigate to TACC's Software List to see where, or if, a particular package is already installed on a particular resource.
If TACC does not have your desired software package already installed, you are welcome to download, build, and install the package in your own account. See Building Third-Party Software in the Software at TACC guide.
The phrase "building software" is a common way to describe the process of producing a machine-readable executable file from source files written in C, Fortran, or some other programming language. In its simplest form, building software involves a simple, one-line call or short shell script that invokes a compiler. More typically, the process leverages the power of makefiles, so you can change a line or two in the source code, then rebuild in a systematic way only the components affected by the change. Increasingly, however, the build process is a sophisticated multi-step automated workflow managed by a special framework like autotools or cmake, intended to achieve a repeatable, maintainable, portable mechanism for installing software across a wide range of target platforms.
This section of the user guide does nothing more than introduce the big ideas with simple one-line examples. You will undoubtedly want to explore these concepts more deeply using online resources. You will quickly outgrow the examples here. We recommend that you master the basics of makefiles as quickly as possible: even the simplest computational research project will benefit enormously from the power and flexibility of a makefile-based build process.
Compilers
Intel Compilers
Intel is the recommended and default compiler suite on Stampede3. Each Intel module also gives you direct access to mkl without loading an mkl module; see Intel MKL for more information.
Important
The latest Intel distribution uses the OneAPI compilers which have different names than the traditional Intel compilers:
| Classic | OneAPI |
|---|---|
icc |
icx |
icpc |
icpx |
ifort |
ifx |
Here are simple examples that use the Intel compiler to build an executable from source code:
$ icx mycode.c # C source file; executable a.out
$ icx main.c calc.c analyze.c # multiple source files
$ icx mycode.c -o myexe # C source file; executable myexe
$ icpx mycode.cpp -o myexe # C++ source file
$ ifx mycode.f90 -o myexe # Fortran90 source file
Compiling a code that uses OpenMP would look like this:
$ icx -qopenmp mycode.c -o myexe # OpenMP
See the published Intel documentation, available both online and in ${TACC_INTEL_DIR}/documentation, for information on optimization flags and other Intel compiler options.
GNU Compilers
The GNU foundation maintains a number of high quality compilers, including a compiler for C (gcc), C++ (g++), and Fortran (gfortran). The gcc compiler is the foundation underneath all three, and the term "gcc" often means the suite of these three GNU compilers.
Load a gcc module to access a recent version of the GNU compiler suite. Avoid using the GNU compilers that are available without a gcc module — those will be older versions based on the "system gcc" that comes as part of the Linux distribution.
Here are simple examples that use the GNU compilers to produce an executable from source code:
$ gcc mycode.c # C source file; executable a.out
$ gcc mycode.c -o myexe # C source file; executable myexe
$ g++ mycode.cpp -o myexe # C++ source file
$ gfortran mycode.f90 -o myexe # Fortran90 source file
$ gcc -fopenmp mycode.c -o myexe # OpenMP; GNU flag is different than Intel
Note that some compiler options are the same for both Intel and GNU (e.g. -o), while others are different (e.g. -qopenmp vs -fopenmp). Many options are available in one compiler suite but not the other. See the online GNU documentation for information on optimization flags and other GNU compiler options.
Compiling and Linking
Building an executable requires two separate steps: (1) compiling (generating a binary object file associated with each source file); and (2) linking (combining those object files into a single executable file that also specifies the libraries that executable needs). The examples in the previous section accomplish these two steps in a single call to the compiler. When building more sophisticated applications or libraries, however, it is often necessary or helpful to accomplish these two steps separately.
Use the -c ("compile") flag to produce object files from source files:
$ icx -c main.c calc.c results.c
Barring errors, this command will produce object files main.o, calc.o, and results.o. Syntax for the Intel and GNU compilers is similar.
You can now link the object files to produce an executable file:
$ icx main.o calc.o results.o -o myexe
The compiler calls a linker utility (usually /bin/ld) to accomplish this task. Again, syntax for other compilers is similar.
Include and Library Paths
Software often depends on pre-compiled binaries called libraries. When this is true, compiling usually requires using the -I option to specify paths to so-called header or include files that define interfaces to the procedures and data in those libraries. Similarly, linking often requires using the -L option to specify paths to the libraries themselves. Typical compile and link lines might look like this:
$ icx -c main.c -I${WORK}/mylib/inc -I${TACC_HDF5_INC} # compile
$ icx main.o -o myexe -L${WORK}/mylib/lib -L${TACC_HDF5_LIB} -lmylib -lhdf5 # link
On Stampede3, both the hdf5 and phdf5 modules define the environment variables $TACC_HDF5_INC and $TACC_HDF5_LIB. Other module files define similar environment variables; see Using Modules to Manage Your Environment for more information.
The details of the linking process vary, and order sometimes matters. Much depends on the type of library: static (.a suffix; library's binary code becomes part of executable image at link time) versus dynamically-linked shared (.so suffix; library's binary code is not part of executable; it's located and loaded into memory at run time). However, the $LD_LIBRARY_PATH environment variable specifies the search path for dynamic libraries. For software installed at the system-level, TACC's modules generally modify LD_LIBRARY_PATH automatically. To see whether and how an executable named myexe resolves dependencies on dynamically linked libraries, execute ldd myexe.
Consult the Intel Math Kernel Library (MKL) section below.
MPI Programs
Intel MPI (module impi) and MVAPICH (module mvapich) are the two MPI libraries available on Stampede3. After loading an impi or mvapich module, compile and/or link using an MPI wrapper (mpicc, mpicxx, mpif90) in place of the compiler:
$ mpicc mycode.c -o myexe # C source, full build
$ mpicc -c mycode.c # C source, compile without linking
$ mpicxx mycode.cpp -o myexe # C++ source, full build
$ mpif90 mycode.f90 -o myexe # Fortran source, full buildThese wrappers call the compiler with the options, include paths, and libraries necessary to produce an MPI executable using the MPI module you're using. To see the effect of a given wrapper, call it with the -show option:
$ mpicc -show # Show compile line generated by call to mpicc; similarly for other wrappersPerformance
Compiler Options
When building software on Stampede3, we recommend using the most recent Intel compiler and Intel MPI library available on Stampede3. The most recent versions may be newer than the defaults. Execute module spider intel and module spider impi to see what's installed. When loading these modules you may need to specify version numbers explicitly (e.g. module load intel/24.0 and module load impi/21.11).
Architecture-Specific Flags
To compile for all the CPU platforms, include -xCORE-AVX512 as a build option. The -x switch allows you to specify a target architecture. The -xCORE-AVX512 is a common subset of Intel's Advanced Vector Extensions 512-bit instruction set that is supported on the Sapphire Rapids (SPR), Ice Lake (ICX) and Sky Lake (SKX) nodes. You should also consider specifying an optimization level using the -O flag:
$ icx -xCORE-AVX512 -O3 mycode.c -o myexe # will run on all nodes
$ ifx -xCORE-AVX512 -O3 mycode.f90 -o myexe # will run on all nodes
$ icpx -xCORE-AVX512 -O3 mycode.cpp -o myexe # will run on all nodesThere are some additional 512 bit optimizations implemented for machine learning on Sapphire Rapids. To compile explicitly for Sapphire Rapids, use the following flags. Besides all other appropriate compiler options, you should also consider specifying an optimization level using the -O flag:
$ icx -xSAPPHIRERAPIDS -O3 mycode.c -o myexe # will run only on SPR nodes
$ ifx -xSAPPHIRERAPIDS -O3 mycode.f90 -o myexe # will run only on SPR nodes
$ icpx -xSAPPHIRERAPIDS -O3 mycode.cpp -o myexe # will run only on SPR nodesSimilarly, to build explicitly for SKX or ICX, you can specify the architecture using -xSKYLAKE-AVX512 or -xICELAKE-SERVER.
It's best to avoid building with -xHost (a flag that means "optimize for the architecture on which I'm compiling now"). The login nodes are SPR nodes. Using -xHost might include instructions that are only supported on SPR nodes.
Don't skip the -x flag in a build: the default is the very old SSE2 (Pentium 4) instruction set. On Stampede3, the module files for the Intel compilers define the environment variable $TACC_VEC_FLAGS that stores the recommended architecture flag described above. This can simplify your builds:
$ echo $TACC_VEC_FLAGS
-xCORE-AVX512
$ icx $TACC_VEC_FLAGS -O3 mycode.c -o myexeIf you use GNU compilers, see GNU x86 Options for information regarding support for SPR, ICX and SKX.
Intel oneAPI Math Kernel Library (oneMKL)
The Intel oneAPI Math Kernel Library (oneMKL) is a collection of highly optimized functions implementing some of the most important mathematical kernels used in computational science, including standardized interfaces to:
- BLAS (Basic Linear Algebra Subroutines), a collection of low-level matrix and vector operations like matrix-matrix multiplication
- LAPACK (Linear Algebra PACKage), which includes higher-level linear algebra algorithms like Gaussian Elimination
- FFT (Fast Fourier Transform), including interfaces based on FFTW (Fastest Fourier Transform in the West)
- Vector Mathematics (VM) functions that implement highly optimized and vectorized versions of special functions like sine and square root.
- ScaLAPACK (Scalable LAPACK), BLACS (Basic Linear Algebra Communication Subprograms), Cluster FFT, and other functionality that provide block-based distributed memory (multi-node) versions of selected LAPACK, BLAS, and FFT algorithms.
oneMKL with Intel C, C++, and Fortran Compilers
There is no oneMKL module for the Intel compilers because you don't need one: the Intel compilers have built-in support for oneMKL. Unless you have specialized needs, there is no need to specify include paths and libraries explicitly. Instead, using oneMKL with the Intel modules requires nothing more than compiling and linking with the -qmkl option.; e.g.
$ icx -qmkl mycode.c
$ ifx -qmkl mycode.cThe -qmkl switch is an abbreviated form of -qmkl=parallel, which links your code to the threaded version of oneMKL. To link to the unthreaded version, use -qmkl=sequential. A third option, -qmkl=cluster, which also links to the unthreaded libraries, is necessary and appropriate only when using ScaLAPACK or other distributed memory packages.
Tip
For additional information, including advanced linking options, see the oneMKL documentation and oneIntel oneMKL Link Line Advisor.
oneMKL with GNU C, C++, and Fortran Compilers
When using a GNU compiler, load the oneMKL module before compiling or running your code, then specify explicitly the oneMKL libraries, library paths, and include paths your application needs. Consult the Intel oneMKL Link Line Advisor for details. A typical compile/link process on a TACC system will look like this:
$ module load gcc
$ module load mkl # available/needed only for GNU compilers
$ gcc -fopenmp -I$MKLROOT/include \
-Wl,-L${MKLROOT}/lib/intel64 \
-lmkl_intel_lp64 -lmkl_core \
-lmkl_gnu_thread -lpthread \
-lm -ldl mycode.cFor your convenience the mkl module file also provides alternative TACC-defined variables like $TACC_MKL_INCLUDE (equivalent to $MKLROOT/include). For more information:
$ module help mkl Using oneMKL as BLAS/LAPACK with Third-Party Software
When your third-party software requires BLAS or LAPACK, you can use oneMKL to supply this functionality. Replace generic instructions that include link options like -lblas or -llapack with the simpler oneMKL approach described above. There is no need to download and install alternatives like OpenBLAS.
Using oneMKL as BLAS/LAPACK with TACC's MATLAB, Python, and R Modules
TACC's MATLAB, Python, and R modules all use threaded (parallel) oneMKL as their underlying BLAS/LAPACK library. These means that even serial codes written in MATLAB, Python, or R may benefit from oneMKL's thread-based parallelism. This requires no action on your part other than specifying an appropriate max thread count for oneMKL; see the section below for more information.
Controlling Threading in oneMKL
Any code that calls oneMKL functions can potentially benefit from oneMKL's thread-based parallelism; this is true even if your code is not otherwise a parallel application. If you are linking to the threaded oneMKL (using -qmkl, -qmkl=parallel, or the equivalent explicit link line), you need only specify an appropriate value for the max number of threads available to oneMKL. You can do this with either of the two environment variables $MKL_NUM_THREADS or $OMP_NUM_THREADS. The environment variable $MKL_NUM_THREADS specifies the max number of threads available to each instance of oneMKL, and has no effect on non-MKL code. If $MKL_NUM_THREADS is undefined, oneMKL uses $OMP_NUM_THREADS to determine the max number of threads available to oneMKL functions. In either case, oneMKL will attempt to choose an optimal thread count less than or equal to the specified value. Note that $OMP_NUM_THREADS defaults to 1 on TACC systems; if you use the default value you will get no thread-based parallelism from oneMKL.
If you are running a single serial, unthreaded application (or an unthreaded MPI code involving a single MPI task per node) it is usually best to give oneMKL as much flexibility as possible by setting the max thread count to the total number of hardware threads on the node (96 on SKX, 160 on ICX, 112 on SPR). Of course things are more complicated if you are running more than one process on a node: e.g. multiple serial processes, threaded applications, hybrid MPI-threaded applications, or pure MPI codes running more than one MPI rank per node. See Intel's Calling oneMKL Functions from Multi-threaded Applications documentation.
Using ScaLAPACK, Cluster FFT, and Other oneMKL Cluster Capabilities
Intel provides substantial and detailed documentation. See Working with the Intel oneAPI Math Kernel Library Cluster Software and Intel oneAPI Math Kernel Library Link Line Advisor for information on linking to the oneMKL Cluster components.
Job Scripts
This section provides sample Slurm job scripts for each Stampede3 node type:
- Sapphire Rapids (SPR)
- Ice Lake (ICX) (ICX)
- Sky Lake (SKX) (SKX)
Each section also contains sample scripts for serial, MPI, OpenMP and hybrid (MPI + OpenMP) programming models. Copy and customize each script for your own applications.
Copy and customize the following jobs scripts by specifying and refining your job's requirements.
- specify the maximum run time with the
-toption. - specify number of nodes needed with the
-Noption - specify total number of MPI tasks with the
-noption - specify the project to be charged with the
-Aoption.
SPR Nodes
Click on a tab for a customizable job-script.
#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 SPR nodes
#
# *** MPI Job in SPR Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch spr.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- Max recommended MPI ranks per SPR node: 112
# (start small, increase gradually).
#
# -- If you're running out of memory, try running
# on more nodes using fewer tasks and/or threads
# per node to give each task access to more memory.
#
# -- Don't worry about task layout. By default, ibrun
# will provide proper affinity and pinning.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and exectuable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p spr # Queue (partition) name
#SBATCH -N 4 # Total # of nodes
#SBATCH -n 448 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 SPR nodes
#
# *** OpenMP Job in SPR Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# -- Copy/edit this script as desired. Launch by executing
# "sbatch spr.openmp.slurm" on a Stampede3 login node.
#
# -- OpenMP codes run on a single node (upper case N = 1).
# OpenMP ignores the value of lower case n,
# but slurm needs a plausible value to schedule the job.
#
# -- Default value of OMP_NUM_THREADS is 1; be sure to change it!
#
# -- Increase thread count gradually while looking for optimal setting.
# If there is sufficient memory available, the optimal setting
# is often 80 (1 thread per core) but may be higher.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and exectuable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p spr # Queue (partition) name
#SBATCH -N 1 # Total # of nodes (must be 1 for OpenMP)
#SBATCH -n 1 # Total # of mpi tasks (should be 1 for OpenMP)
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=112 # this is 1 thread/core; may want to start lower
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch OpenMP code...
./myprogram # Do not use ibrun or any other MPI launcher#!/bin/bash
#----------------------------------------------------
# Example Slurm job script
# for TACC Stampede3 SPR nodes
#
# *** Hybrid Job in SPR Queue ***
#
# This sample script specifies:
# 10 nodes (capital N)
# 40 total MPI tasks (lower case n); this is 4 tasks/node
# 28 OpenMP threads per MPI task (112 threads per node)
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch spr.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- In most cases it's best to keep
# ( MPI ranks per node ) x ( threads per rank )
# to a number no more than 112 (total cores).
#
# -- If you're running out of memory, try running
# fewer tasks and/or threads per node to give each
# process access to more memory.
#
# -- If you're running out of memory, try running
# on more nodes using fewer tasks and/or threads
# per node to give each task access to more memory.
#
# -- Don't worry about task layout. By default, ibrun
# will provide proper affinity and pinning.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and exectuable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p icx # Queue (partition) name
#SBATCH -N 10 # Total # of nodes
#SBATCH -n 40 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=28
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec
ICX Nodes
Click on a tab for a customizable job-script.
#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 ICX nodes
#
# *** MPI Job in ICX Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch icx.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- Max recommended MPI ranks per ICX node: 80
# (start small, increase gradually).
#
# -- If you're running out of memory, try running
# on more nodes using fewer tasks and/or threads
# per node to give each task access to more memory.
#
# -- Don't worry about task layout. By default, ibrun
# will provide proper affinity and pinning.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and exectuable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p icx # Queue (partition) name
#SBATCH -N 4 # Total # of nodes
#SBATCH -n 320 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec
#!/bin/bash
#----------------------------------------------------
#
# Sample Slurm job script
# for TACC Stampede3 ICX nodes
#
# *** OpenMP Job in ICX Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# -- Copy/edit this script as desired. Launch by executing
# "sbatch icx.openmp.slurm" on a Stampede3 login node.
#
# -- OpenMP codes run on a single node (upper case N = 1).
# OpenMP ignores the value of lower case n,
# but slurm needs a plausible value to schedule the job.
#
# -- Default value of OMP_NUM_THREADS is 1; be sure to change it!
#
# -- Increase thread count gradually while looking for optimal setting.
# If there is sufficient memory available, the optimal setting
# is often 80 (1 thread per core) but may be higher.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and exectuable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p icx # Queue (partition) name
#SBATCH -N 1 # Total # of nodes (must be 1 for OpenMP)
#SBATCH -n 1 # Total # of mpi tasks (should be 1 for OpenMP)
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=80 # this is 1 thread/core; may want to start lower
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch OpenMP code...
./myprogram # Do not use ibrun or any other MPI launcher
#!/bin/bash
#----------------------------------------------------
# Example Slurm job script
# for TACC Stampede3 ICX nodes
#
# *** Hybrid Job in ICX Queue ***
#
# This sample script specifies:
# 10 nodes (capital N)
# 40 total MPI tasks (lower case n); this is 4 tasks/node
# 20 OpenMP threads per MPI task (80 threads per node)
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch icx.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- In most cases it's best to keep
# ( MPI ranks per node ) x ( threads per rank )
# to a number no more than 80 (total cores).
#
# -- If you're running out of memory, try running
# fewer tasks and/or threads per node to give each
# process access to more memory.
#
# -- If you're running out of memory, try running
# on more nodes using fewer tasks and/or threads
# per node to give each task access to more memory.
#
# -- Don't worry about task layout. By default, ibrun
# will provide proper affinity and pinning.
#
# -- You should always run out of $SCRATCH. Your input
# files, output files, and executable should be
# in the $SCRATCH directory hierarchy.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p icx # Queue (partition) name
#SBATCH -N 10 # Total # of nodes
#SBATCH -n 40 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=20
# Always run your jobs out of $SCRATCH. Your input files, output files,
# and exectuable should be in the $SCRATCH directory hierarchy.
# Change directories to your $SCRATCH directory where your executable is
cd $SCRATCH
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec
SKX Nodes
Click on a tab for a customizable job-script.
#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 SKX nodes
#
# *** Serial Job in SKX Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Copy/edit this script as desired. Launch by executing
# "sbatch skx.serial.slurm" on a Stampede3 login node.
#
# -- Serial codes run on a single node (upper case N = 1).
# A serial code ignores the value of lower case n,
# but slurm needs a plausible value to schedule the job.
#
# -- For a good way to run multiple serial executables at the
# same time, execute "module load pylauncher" followed
# by "module help pylauncher".
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p skx # Queue (partition) name
#SBATCH -N 1 # Total # of nodes (must be 1 for serial)
#SBATCH -n 1 # Total # of mpi tasks (should be 1 for serial)
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Launch serial code...
./myprogram # Do not use ibrun or any other MPI launcher
# ---------------------------------------------------#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 SKX nodes
#
# *** MPI Job in SKX Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch skx.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- Max recommended MPI ranks per SKX node: 48
# (start small, increase gradually).
#
# -- If you're running out of memory, try running
# fewer tasks per node to give each task more memory.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p skx # Queue (partition) name
#SBATCH -N 4 # Total # of nodes
#SBATCH -n 32 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec
#!/bin/bash
#----------------------------------------------------
# Sample Slurm job script
# for TACC Stampede3 SKX nodes
#
# *** OpenMP Job in SKX Queue ***
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# -- Copy/edit this script as desired. Launch by executing
# "sbatch skx.openmp.slurm" on a Stampede3 login node.
#
# -- OpenMP codes run on a single node (upper case N = 1).
# OpenMP ignores the value of lower case n,
# but slurm needs a plausible value to schedule the job.
#
# -- Default value of OMP_NUM_THREADS is 1; be sure to change it!
#
# -- Increase thread count gradually while looking for optimal setting.
# If there is sufficient memory available, the optimal setting
# is often 48 (1 thread per core) but may be higher.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p skx # Queue (partition) name
#SBATCH -N 1 # Total # of nodes (must be 1 for OpenMP)
#SBATCH -n 1 # Total # of mpi tasks (should be 1 for OpenMP)
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=48 # this is 1 thread/core; may want to start lower
# Launch OpenMP code...
./myprogram # Do not use ibrun or any other MPI launcher
#!/bin/bash
#----------------------------------------------------
# Example Slurm job script
# for TACC Stampede3 SKX nodes
#
# *** Hybrid Job in SKX Queue ***
#
# This sample script specifies:
# 10 nodes (capital N)
# 40 total MPI tasks (lower case n); this is 4 tasks/node
# 12 OpenMP threads per MPI task (48 threads per node)
#
# Last revised: 23 April 2024
#
# Notes:
#
# -- Launch this script by executing
# "sbatch skx.mpi.slurm" on Stampede3 login node.
#
# -- Use ibrun to launch MPI codes on TACC systems.
# Do not use mpirun or mpiexec.
#
# -- In most cases it's best to keep
# ( MPI ranks per node ) x ( threads per rank )
# to a number no more than 48 (total cores).
#
# process access to more memory.
#
# -- IMPI and MVAPICH both do sensible process pinning by default.
#
#----------------------------------------------------
#SBATCH -J myjob # Job name
#SBATCH -o myjob.o%j # Name of stdout output file
#SBATCH -e myjob.e%j # Name of stderr error file
#SBATCH -p skx # Queue (partition) name
#SBATCH -N 10 # Total # of nodes
#SBATCH -n 40 # Total # of mpi tasks
#SBATCH -t 01:30:00 # Run time (hh:mm:ss)
#SBATCH --mail-user=username@tacc.utexas.edu
#SBATCH --mail-type=all # Send email at begin and end of job
#SBATCH -A myproject # Allocation name (req'd if you have more than 1)
# Other commands must follow all #SBATCH directives...
module list
pwd
date
# Set thread count (default value is 1)...
export OMP_NUM_THREADS=12
# Launch MPI code...
ibrun ./myprogram # Use ibrun instead of mpirun or mpiexec
Job Management
In this section, we present several Slurm commands and other utilities that are available to help you plan and track your job submissions as well as check the status of the Slurm queues.
Important
When interpreting queue and job status, remember that Stampede3 does not operate on a first-come-first-served basis. Instead, the sophisticated, tunable algorithms built into Slurm attempt to keep the system busy, while scheduling jobs in a way that is as fair as possible to everyone. At times this means leaving nodes idle ("draining the queue") to make room for a large job that would otherwise never run. It also means considering each user's "fair share", scheduling jobs so that those who haven't run jobs recently may have a slightly higher priority than those who have.
Monitoring Queue Status
Monitor queue status via Slurm's sinfo command and/or TACC's qlimits utility.
TACC's qlimits command
To display resource limits for the Lonestar queues, execute: qlimits. The result is real-time data; the corresponding information in this document's table of Stampede3 queues may lag behind the actual configuration that the qlimits utility displays.
Slurm's sinfo command
Slurm's sinfo command allows you to monitor the status of the queues. If you execute sinfo without arguments, you'll see a list of every node in the system together with its status. To skip the node list and produce a tight, alphabetized summary of the available queues and their status, execute:
login1$ sinfo -S+P -o "%18P %8a %20F" # compact summary of queue statusThis command's output might look like this:
PARTITION AVAIL NODES(A/I/O/T)
icx up 103/2/7/112
skx up 402/6/32/440
skx-dev* up 6/70/4/80The AVAIL column displays the overall status of each queue (up or down), while the column labeled NODES(A/I/O/T) shows the number of nodes in each of several states ("Allocated", "Idle", "Offline", and "Total"). Execute man sinfo for more information. Use caution when reading the generic documentation, however: some available fields are not meaningful or are misleading on Stampede3 (e.g. TIMELIMIT, displayed using the %l option).
Monitoring Job Status
Monitor your job's status in the queue via Slurm's squeue command and/or TACC's showq utility.
Slurm's squeue command
Slurm's squeue command displays the state of all queued and running jobs.
login1$ squeue # show all jobs in all queues
login1$ squeue -u bjones # show all jobs owned by bjones
login1$ man squeue # more infoThe squeue command's default output format lists all nodes assigned to displayed jobs; this can make the output difficult to read. See the example below for a handy variation that suppresses the nodelist:
Tip
The squeue command's default output format lists all nodes assigned to displayed jobs; this can make the output difficult to read. See the example below for a handy variation that suppresses the nodelist:
login1$ squeue -o "%.10i %.12P %.12j %.9u %.2t %.9M %.6D" # suppress nodelistJob and Queue Status Meanings
The squeue command's output displays two columns of interest, the column labeled ST displays each job's status, and the last column, labeled NODELIST/REASON, includes a nodelist for running/completing jobs, or a reason for pending jobs. See Table 10 and Table 11 below for detailed explanations.
login1$ squeue -u slindsey | more
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
10454 icx l4chcoo2 tg123456 PD 0:00 1 (QOSMaxJobsPerUserLimit)
8018 icx l4bident tg123456 R 14:57:56 1 c461-218
10945 icx SM34_687 slindsey R 27:30 10 c463-[218-227]
10940 icx SM34_685 slindsey R 28:44 1 c463-214
8936 icx mark5.1 bjones R 21:53:14 12 c460-207,c461-[206-212,221-224]
9795 icx mark1.2 bjones R 12:08:59 10 c460-[220-227],c461-[219-220]
10956 icx i2 sniffjck R 14:14 4 c460-[208-211]
10997 skx NAME rtoscano CG 1:13 4 c477-[092-094,101]
10996 skx NAME rtoscano CG 2:44 4 c479-034,c490-[082-084]
9609 skx sample-s tg987654 PD 0:00 1 (QOSMaxJobsPerUserLimit)
11002 skx NAME ashleyp PD 0:00 4 (Priority)
11004 skx NAME ashleyp PD 0:00 4 (Priority)
11000 skx NAME ashleyp PD 0:00 4 (Resources)
10673 skx trD4.204 jemerson PD 0:00 4 (Dependency)
10457 skx l4dimcha tg123456 PD 0:00 2 (QOSMaxJobsPerUserLimit)
10563 skx lcdm_bas kellygue PD 0:00 1 (Dependency)
10961 skx d2_12 tg111111 PD 0:00 1 (QOSMaxJobsPerUserLimit)squeue outputTable 10. Job Status Meanings
| Status Code | Status | Description |
|---|---|---|
CA |
CANCELLED | Job was explicitly cancelled by the user or system administrator |
CD |
COMPLETED | Job has terminated all processes on all nodes with an exit code of zero. |
CG |
COMPLETING | Job is in the process of completing. Some processes on some nodes may still be active. |
F |
FAILED | Job terminated with non-zero exit code or other failure condition. |
NF |
NODE_FAIL | Job terminated due to failure of one or more allocated nodes. |
PD |
PENDING | Job is awaiting resource allocation. |
PR |
PREEMPTED | Job terminated due to preemption. |
R |
RUNNING | Job has an allocation and is currently running. |
TO |
TIMEOUT | Job terminated upon reaching its time limit. |
Table 11. Pending Jobs Reason
The last column, labeled NODELIST/REASON, includes a nodelist for running/completing jobs, or a reason for pending jobs.
NODELIST/REASON |
Description |
|---|---|
Resources |
The necessary combination of nodes/GPUs for your job are not available |
Priority |
There are other jobs in the queue with a higher priority |
Dependency |
The job will not start until the dependency specified by you is satisfied. |
ReqNodeNotAvailable |
If you submit a job before a scheduled system maintenance period, and the job cannot complete before the maintenance begins, your job will run when the maintenance/reservation concludes. The job will remain in the PD state until Stampede3 returns to production. |
QOSMaxJobsPerUserLimit |
The number of your jobs queued exceeds that queue's limits. These jobs will run once your previous jobs have ended. |
Tip
The --start option to the squeue command displays job start times, including very rough estimates for the expected start times of some pending jobs that are relatively high in the queue:
login1$ squeue --start -j 167635 # display estimated start time for job 167635TACC's showq utility
TACC's showq utility mimics a tool that originated in the PBS project, and serves as a popular alternative to the Slurm squeue command:
login1$ showq # show all jobs; default format
login1$ showq -u # show your own jobs
login1$ showq -U bjones # show jobs associated with user bjones
login1$ showq -h # more infoThe output groups jobs in four categories: ACTIVE, WAITING, BLOCKED, and COMPLETING/ERRORED. A BLOCKED job is one that cannot yet run due to temporary circumstances (e.g. a pending maintenance or other large reservation.).
If your waiting job cannot complete before a maintenance/reservation begins, showq will display its state as **WaitNod** ("Waiting for Nodes"). The job will remain in this state until Stampede3 returns to production.
Since TACC charges by the node rather than core, showq's default format now reports total nodes associated with a job rather than cores, tasks, or hardware threads. Run showq with the -l option to display the number of cores and the job's queue.
Dependent Jobs using sbatch
You can use sbatch to help manage workflows that involve multiple steps: the --dependency option allows you to launch jobs that depend on the completion (or successful completion) of another job. For example you could use this technique to split into three jobs a workflow that requires you to (1) compile on a single node; then (2) compute on 40 nodes; then finally (3) post-process your results using 4 nodes.
login1$ sbatch --dependency=afterok:173210 myjobscriptWarning
It is not possible to add resources to a job (e.g. allow more time, increase number of nodes) once you've submitted the job to the queue.
For more information see the Slurm online documentation. Note that you can use $SLURM_JOBID from one job to find the jobid you'll need to construct the sbatch launch line for a subsequent one. But also remember that you can't use sbatch to submit a job from a compute node.
Inspecting Running and Completed Jobs
-
To view some accounting data associated with your own jobs, use
sacct:login1$ sacct --starttime 2026-05-01 # show jobs that started on or after this date -
To cancel a pending or running job, first determine its jobid, then use
scancel:login1$ squeue -u bjones # one way to determine jobid JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON) 170361 icx spec12 bjones PD 0:00 32 (Resources) login1$ scancel 170361 # cancel job -
For detailed information about the configuration of a specific job, use
scontrol:login1$ scontrol show job=170361
Programming and Performance
Programming for performance is a broad and rich topic. While there are no shortcuts, there are certainly some basic principles that are worth considering any time you write or modify code.
Timing and Profiling
Measure performance and experiment with both compiler and runtime options. This will help you gain insight into issues and opportunities, as well as recognize the performance impact of code changes and temporary system conditions.
Measuring performance can be as simple as prepending the shell keyword time or the command perf stat to your launch line. Both are simple to use and require no code changes. Typical calls look like this:
$ perf stat ./a.out # report basic performance stats for a.out
$ time ./a.out # report the time required to execute a.out
$ time ibrun ./a.out # time an MPI code
$ ibrun time ./a.out # crude timings for each MPI task (no rank info)As your needs evolve you can add timing intrinsics to your source code to time specific loops or other sections of code. There are many such intrinsics available; some popular choices include gettimeofday, MPI_Wtime and omp_get_wtime. The resolution and overhead associated with each of these timers is on the order of a microsecond.
It can be helpful to compare results with different compiler and runtime options: e.g. with and without vectorization, threading, or Lustre striping. You may also want to learn to use profiling tools like Intel VTune Amplifier (module load vtune) or GNU gprof.
Data Locality
Appreciate the high cost (performance penalty) of moving data from one node to another, from disk to memory, and even from memory to cache. Write your code to keep data as close to the computation as possible: e.g. in memory when needed, and on the node that needs it. This means keeping in mind the capacity and characteristics of each level of the memory hierarchy when designing your code and planning your simulations.
When possible, best practice also calls for so-called "stride 1 access" - looping through large, contiguous blocks of data, touching items that are adjacent in memory as the loop proceeds. The goal here is to use "nearby" data that is already in cache rather than going back to main memory (a cache miss) in every loop iteration.
To achieve stride 1 access you need to understand how your program stores its data. Here C and C++ are different than (in fact the opposite of) Fortran. C and C++ are row-major: they store 2d arrays a row at a time, so elements a[3][4] and a[3][5] are adjacent in memory. Fortran, on the other hand, is column-major: it stores a column at a time, so elements a(4,3) and a(5,3) are adjacent in memory. Loops that achieve stride 1 access in the two languages look like this:
| Fortran example | C example |
|---|---|
real*8 :: a(m,n), b(m,n), c(m,n)
...
! inner loop strides through col i
do i=1,n
do j=1,m
a(j,i)=b(j,i)+c(j,i)
end do
end do
| double a[m][n], b[m][n], c[m][n]; ... // inner loop strides through row i for (i=0;i |
Vectorization
Give the compiler a chance to produce efficient, vectorized code. The compiler can do this best when your inner loops are simple (e.g. no complex logic and a straightforward matrix update like the ones in the examples above), long (many iterations), and avoid complex data structures (e.g. objects). See Intel's note on Programming Guidelines for Vectorization for a nice summary of the factors that affect the compiler's ability to vectorize loops.
It's often worthwhile to generate optimization and vectorization reports when using the Intel compiler. This will allow you to see exactly what the compiler did and did not do with each loop, together with reasons why.
The literature on optimization is vast. Some places to begin a systematic study of optimization on Intel processors include: Intel's Modern Code resources; and the Intel Optimization Reference Manual.
Programming and Performance: SPR, ICX, and SKX
Clock Speed: The published nominal clock speed of the Stampede3 SPR processors is 1.9 GHz, for the SKX processors it is 2.1GHz, and for the ICX processors it is 2.3GHz. But actual clock speed varies widely: it depends on the vector instruction set, number of active cores, and other factors affecting power requirements and temperature limits. At one extreme, a single serial application using the AVX2 instruction set may run at frequencies approaching 3.7GHz, because it's running on a single core (in fact a single hardware thread). At the other extreme, a large, fully-threaded MKL dgemm (a highly vectorized routine in which all cores operate at nearly full throttle) may run at 1.9 GHz.
Vector Optimization and AVX2: In some cases, using the AVX2 instruction set may produce better performance than AVX512. This is largely because cores can run at higher clock speeds when executing AVX2 code. To compile for AVX2, replace the multi-architecture flags described above with the single flag -xCORE-AVX2. When you use this flag you will be able to build and run on any Stampede3 node.
Vector Optimization and 512-Bit ZMM Registers. If your code can take advantage of wide 512-bit vector registers, you may want to try compiling for with (for example):
-xCORE-AVX512 -qopt-zmm-usage=high
The qopt-zmm-usage flag affects the algorithms the compiler uses to decide whether to vectorize a given loop with AVX51 intrinsics (wide 512-bit registers) or AVX2 code (256-bit registers). When the flag is set to -qopt-zmm-usage=low (the default when compiling for SPR, ICX, and SKX using CORE-AVX512), the compiler will choose AVX2 code more often; this may or may not be the optimal approach for your application. See the recent Intel white paper, the compiler documentation, the compiler man pages, and the notes above for more information.
Task Affinity: If you run one MPI application at a time, the ibrun MPI launcher will spread each node's tasks evenly across an SPR, ICX, or SKX node's two sockets, with consecutive tasks occupying the same socket when possible.
Hardware Thread Numbering. Execute lscpu or lstopo on SPR, ICX, or SKX nodes to see the numbering scheme for cores. Note that core numbers alternate between the sockets on SKX and ICX nodes: even numbered cores are on NUMA node 0, while odd numbered cores are on NUMA node 1.
Tuning the Performance Scaled Messaging (PSM2) Library. When running on SKX with MVAPICH, setting the environment variable PSM2_KASSIST_MODE to the value none may or may not improve performance. For more information see the MVAPICH User Guide. Do not use this environment variable with IMPI; doing so may degrade performance. The ibrun launcher will eventually control this environment variable automatically.
File Operations: I/O Performance
This section includes general advice intended to help you achieve good performance during file operations. See Managing I/O at TACC and TACC Training page for additional information on I/O performance.
Follow the advice in TACC Good Conduct Guide to avoid stressing the file system.
Aggregate file operations: Open and close files once. Read and write large, contiguous blocks of data at a time; this requires understanding how a given programming language uses memory to store arrays.
Be smart about your general strategy: When possible avoid an I/O strategy that requires each process to access its own files; such strategies don't scale well and are likely to stress a parallel file system. A better approach is to use a single process to read and write files. Even better is genuinely parallel MPI-based I/O.
Use parallel I/O libraries: Leave the details to a high performance package like MPI-IO (built into MPI itself), parallel HDF5 (module load phdf5), and parallel netCDF (module load pnetcdf).
When using the Intel Fortran compiler, compile with the -assume buffered_io flag. Equivalently, set the environment variable FORT_BUFFERED=TRUE. Doing otherwise can dramatically slow down access to variable length unformatted files. More generally, direct access in Fortran is typically faster than sequential access, and accessing a binary file is faster than ASCII.
Machine Learning
Follow these instructions to begin using Intel's Conda environment with PyTorch and Tensorflow on Stampede3.
-
First, do an initial one-time setup of the conda environment, then log out.
login2.stampede3(1003)$ module load python login2.stampede3(1004)$ module save Saved current collection of modules to: "default" login2.stampede3(1005)$ conda init bash login2.stampede3(1006)$ logout logout Connection to login2.stampede3.tacc.utexas.edu closed. -
Log back into Stampede3, then activate either the PyTorch or Tensorflow environment.
localhost$ ssh stampede3.tacc.utexas.edu ... (base) login1.stampede3(1003)$ conda activate pytorch (pytorch) login1.stampede3(1004)$
Python
Python on Stampede3 has been made into a module to mirror the environments of TACC others machines. Load python like so:
$ module load pythonJupyter Notebooks
Unlike TACC's other HPC resources, Jupyter is not installed with the Python module on Stampede3. In order to use Jupyter notebooks, you must install notebooks locally with the following one-time setup:
-
Log into Stampede3, then edit your
.bashrcfile. Add the following line to the "SECTION 1" portion of the file to update your$PATHenvironment variable.export PATH=$PATH:$HOME/.local/bin -
Then install notebooks locally:
pip install --user notebook==6.0.3
This setup enables the TACC Analysis Portal to find the non-standard-location Jupyter-lab or Jupyter-notebook commands.
If you prefer the old Jupyter notebook style then move the Jupyter lab executable to something else. Note that the TAP portal software is expecting a particular version of Jupyter. This version is consistent across TACC systems.
Help Desk
Important
Submit a help desk ticket at any time via the TACC User Portal. Be sure to include "Stampede3" in the Resource field.
TACC Consulting operates from 8am to 5pm CST, Monday through Friday, except for holidays. Help the consulting staff help you by following these best practices when submitting tickets.
-
Do your homework before submitting a help desk ticket. What does the user guide and other documentation say? Search the internet for key phrases in your error logs; that's probably what the consultants answering your ticket are going to do. What have you changed since the last time your job succeeded?
-
Describe your issue as precisely and completely as you can: what you did, what happened, verbatim error messages, other meaningful output.
Tip
When appropriate, include as much meta-information about your job and workflow as possible including:
- directory containing your build and/or job script
- all modules loaded
- relevant job IDs
- any recent changes in your workflow that could affect or explain the behavior you're observing.
-
Subscribe to Stampede3 User News. This is the best way to keep abreast of maintenance schedules, system outages, and other general interest items.
-
Have realistic expectations. Consultants can address system issues and answer questions about Stampede3. But they can't teach parallel programming in a ticket, and may know nothing about the package you downloaded. They may offer general advice that will help you build, debug, optimize, or modify your code, but you shouldn't expect them to do these things for you.
-
Be patient. It may take a business day for a consultant to get back to you, especially if your issue is complex. It might take an exchange or two before you and the consultant are on the same page. If the admins disable your account, it's not punitive. When the file system is in danger of crashing, or a login node hangs, they don't have time to notify you before taking action.
References
- Bash Users’ Startup Files: Quick Start Guide
idevat TACC- GNU documentation
- Intel software documentation
- Lmod's online documentation
- Multi-Factor Authentication at TACC
- Princeton Research Computing's Slurm Knowledge Base
- Sharing Project Files on TACC Systems
- Slurm online documentation
- TACC Analysis Portal